Multithreading pod mikroskopem
Multithreading
Procesor v zařízení na kterém čtete tento článek má téměř jistě více než jedno jádro. Více jader v procesoru dává operačnímu systému možnost spouštět víc procesů naráz. Někdy, ale programátor sám chce použít více jader, potom poprosí systém o další execution thread a zadá mu práci. A podle dovedností programátora teď program buď běží rychleji, běží stejně rychle, je zaseklý v dead locku nebo se chová neočekávaně kvli race condition.
V tomhle blogpostu vám představím základ C pthread API a řeknu vám něco o synchronizačních datových strukturách.
Vlákna
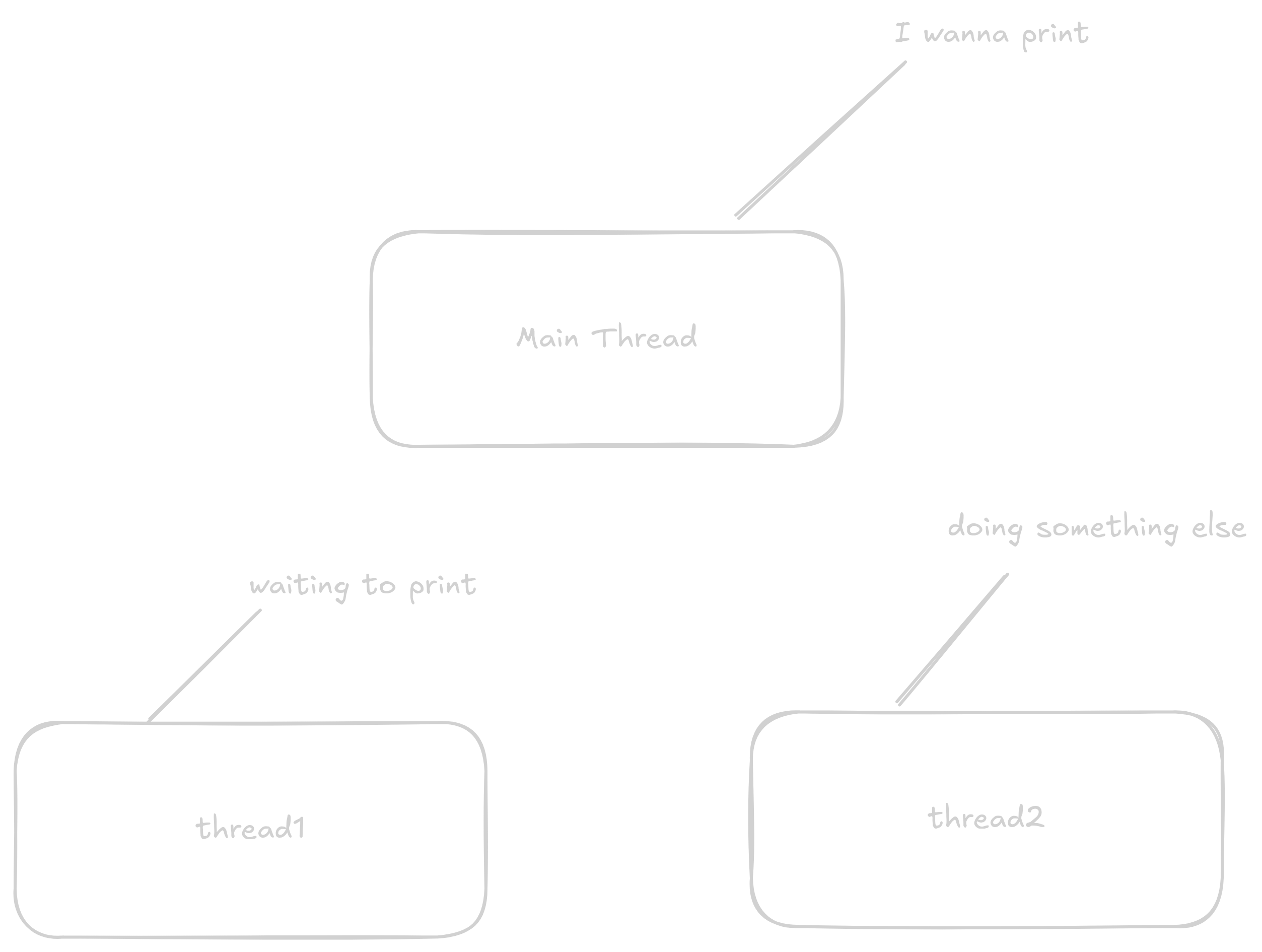
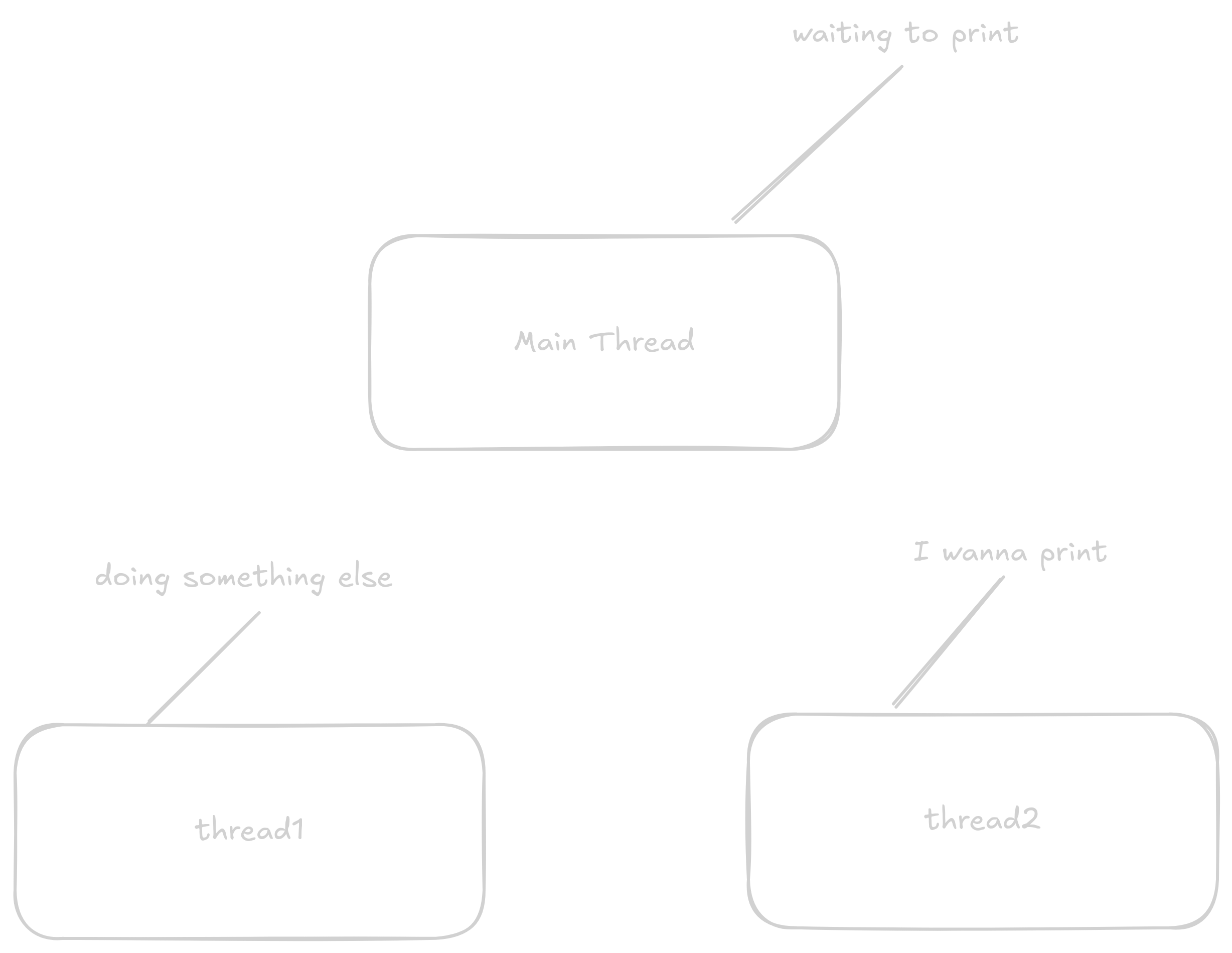
Threads nebo vlákna jsou jména pro fyzická jádra v procesoru která můžou naráz spouštět kód.
Nejdůležitější je právě pochopit ten koncept že dělají práci naráz.
Thready prostě pracují a ze základu spolu nesdílí moc informací co zrovna dělají.
Pojďme si to ukázat na následujícím příkladu.
Tento program vytvoří dva další thready které vytisknou 5 nějakou zprávu zatímco hlavní thread tiskne "Main Thread".
(Hlavní thread je nejdůležitější jádro procesu které když skončí tak systém automatikcy ukončí všechny ostatní jádra bez ohledu zda dokončily svou práci)
// naimportujeme pthreads knihovnu
#include <pthread.h>
#include <stdio.h>
// funkce 10x vytiskne zprávu
void *print_message_function(void *ptr) {
for (int i = 0; i < 5; i++) {
printf("%s\n", (char *)ptr /* argument dostáváme do naší funkce v typu void pointer
(pointer který ukazuje na data neznámé velikosti),
ale printf očekává pointer na char,
proto musíme pointer přetypovat */);
}
// vrátíme null pointer
return NULL;
}
int main() {
pthread_t thread1, thread2;
char *message1 = "Thread 1";
char *message2 = "Thread 2";
// Zde vytvoříme dvě vlákna která začnou spouštět funkci
// print_message_function
// první argument je pointer do kterého se nám uloží handle na thread
// druhý argument nás dnes nezajímá
// třetí argument je pointer na funkci kterou chceme aby thread spouštěl
// čtvrtý argument je pointer na data která chceme funkci předat
// funkce vrací 0 pokud vše proběhlo v pořádku, pro tento malý program hodnotu
// zahazuji
pthread_create(&thread1, NULL, print_message_function, (void *)message1);
pthread_create(&thread2, NULL, print_message_function, (void *)message2);
// zde hlavní jádro dělá nějakou práci
for (int i = 0; i < 5; i++) {
printf("Main Thread\n");
}
// pthread_join je funkce která blokuje dokud daný hread nedokončí svoji práci
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}Výstup tohoto programu bude vypadat nějak takto:
Thread 1
Thread 2
Thread 2
Thread 1
Thread 1
Thread 1
Thread 1
Main Thread
Main Thread
Main Thread
Main Thread
Main Thread
Thread 2
Thread 2
Thread 2nebo takto:
Main Thread
Main Thread
Thread 1
Thread 1
Thread 1
Thread 1
Thread 1
Main Thread
Main Thread
Main Thread
Thread 2
Thread 2
Thread 2
Thread 2
Thread 2Nebo ještě úplně jakkoliv jinak, protože záleží jak zrovna vyšlo časování toho jaká thread zrovna co dělá.
Pojďme se kouknout na trochu jiný příklad.
#include <pthread.h>
#include <stdio.h>
int count = 0;
void *inc_count(void *arg) {
int i;
// přičíst 100 000 k counter jedna po jedné
for (i = 0; i < 100000; i++) {
count++;
}
return NULL;
}
int main() {
pthread_t t1, t2;
// vytvořit thready
pthread_create(&t1, NULL, inc_count, NULL);
pthread_create(&t2, NULL, inc_count, NULL);
// počkat než thready dokončí svoji práci
pthread_join(t1, NULL);
pthread_join(t2, NULL);
// vytisknout výsledek počítání
// Ten výsledek bude 200000 určitě když dva thready přičtou 100 000
printf("count = %d\n", count);
return 0;
}Výsledek tohoto programu nebude count = 200000 protože jednotlivé thready přepisují svoje výsledky.
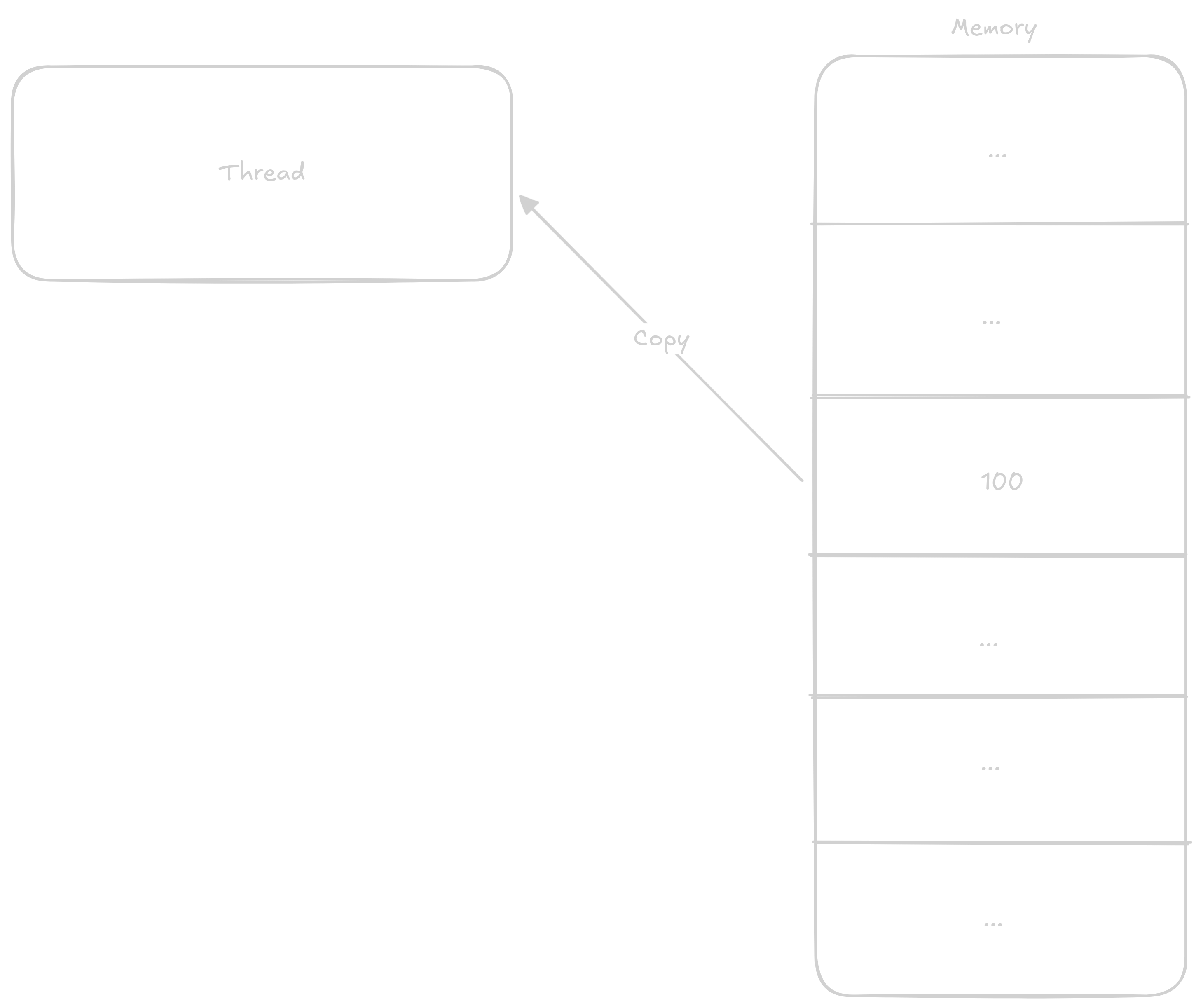
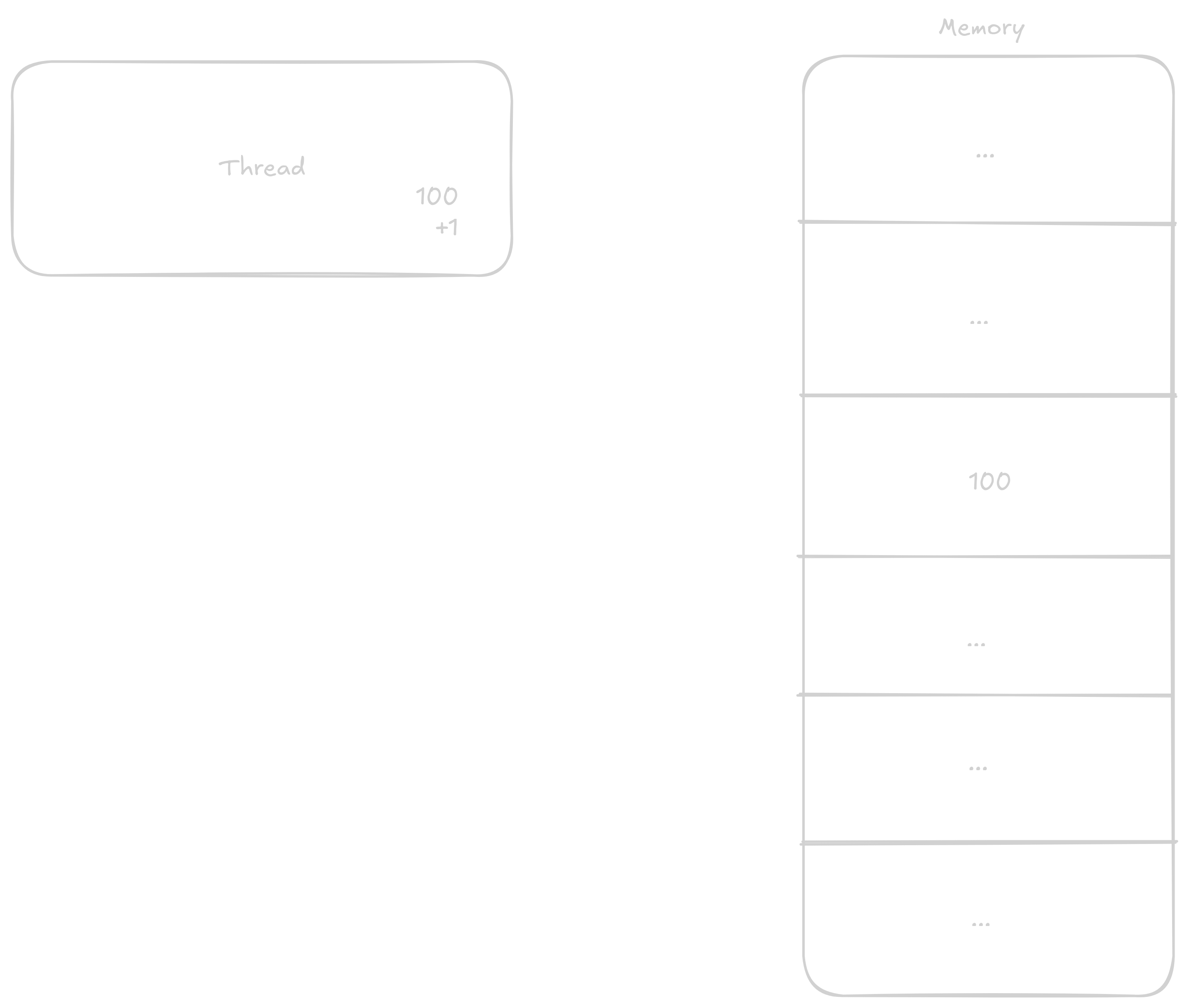
Normálně když chce thread k číslu přičíst 1 postupuje v těchto krocích:
Načtě si do registru hodnotu z adresy kde číslo je
Přičte k němu
1Vrátí výsledek zpátky do paměti


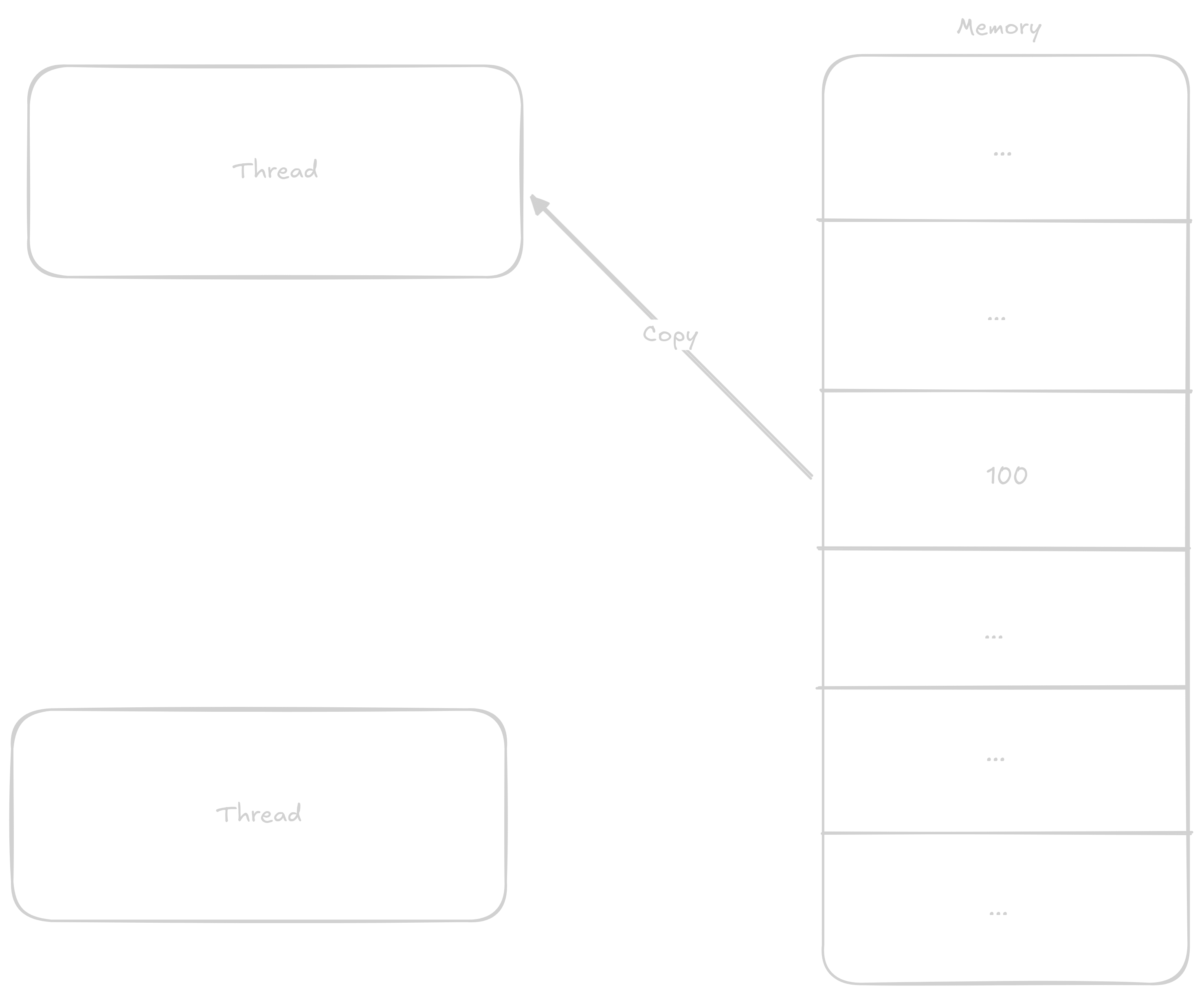
V případě že k proměnné budou přičítat dvě vlákna naráz kroky se můžou promíchat třeba nějak takto:
Vlákno jedna si načte hodnotu do registru
Vlákno dva si načte hodnotu do registru
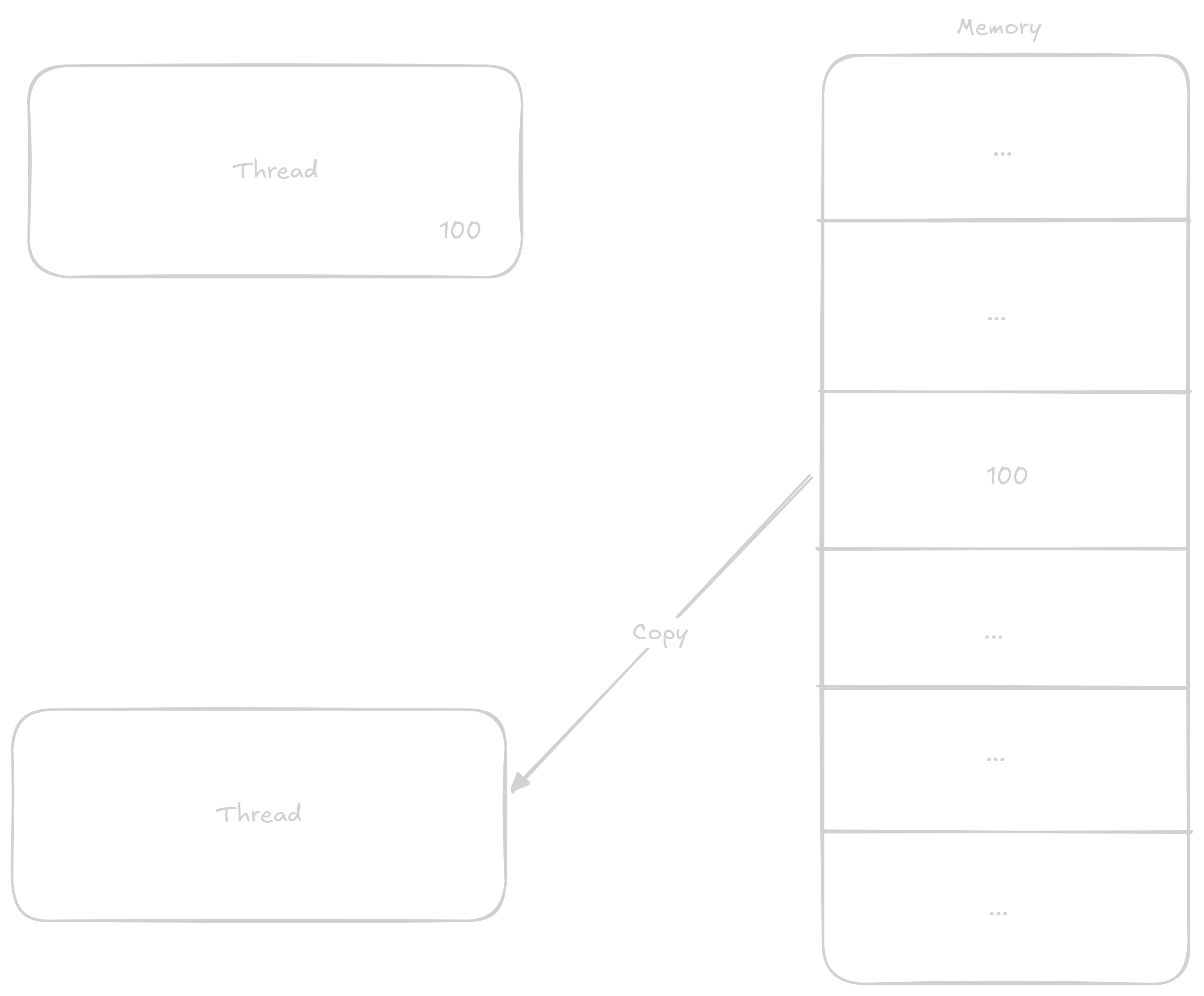
Vlákno jedna přičte k hodnotě
1Vlákno jedna vrátí novoud hodnotu do pamti
Vlákno dva přičte k svojí již staré hodnotě
1Vlákno dva zapíše již zastaralou hodnotu do paměti
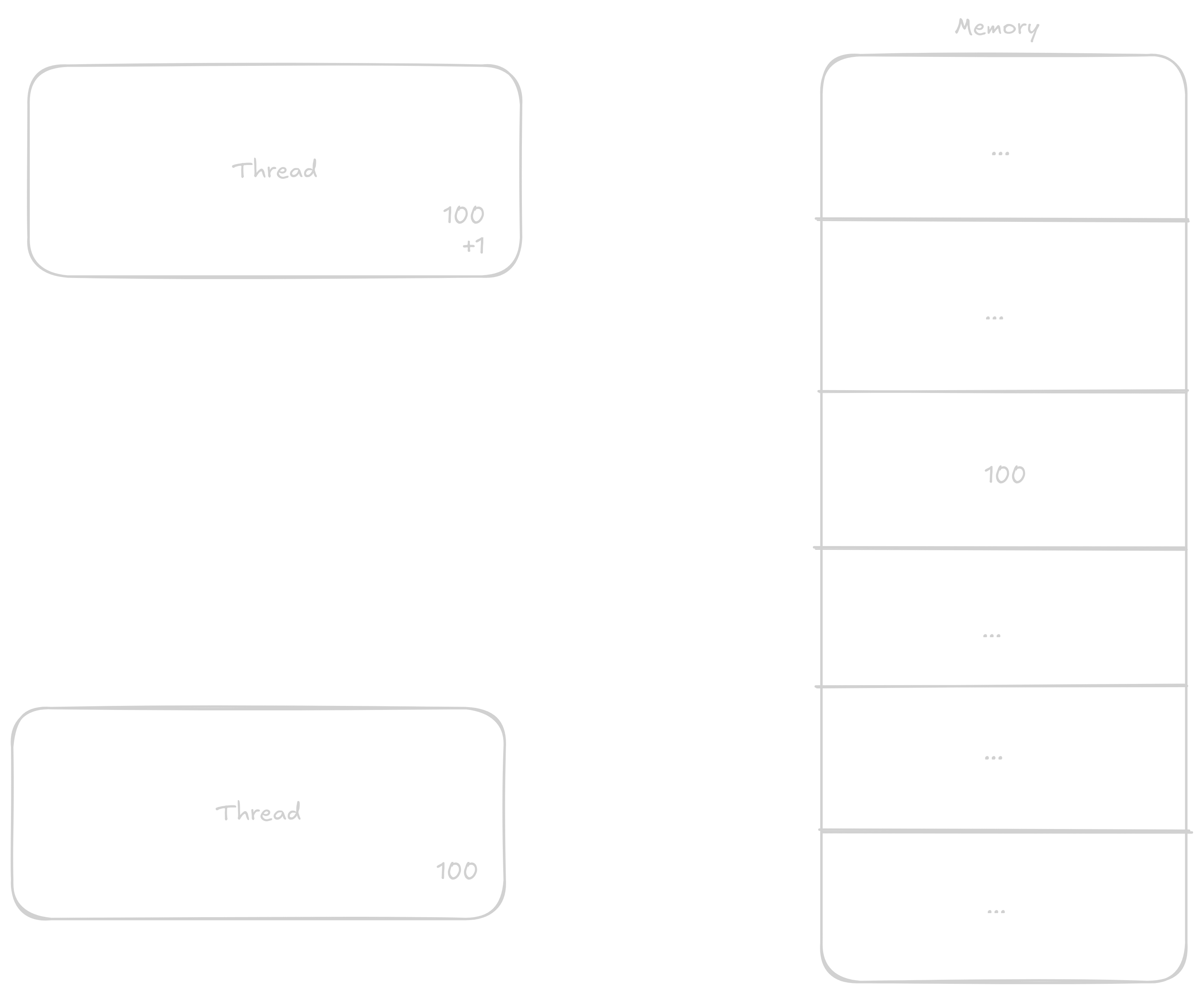
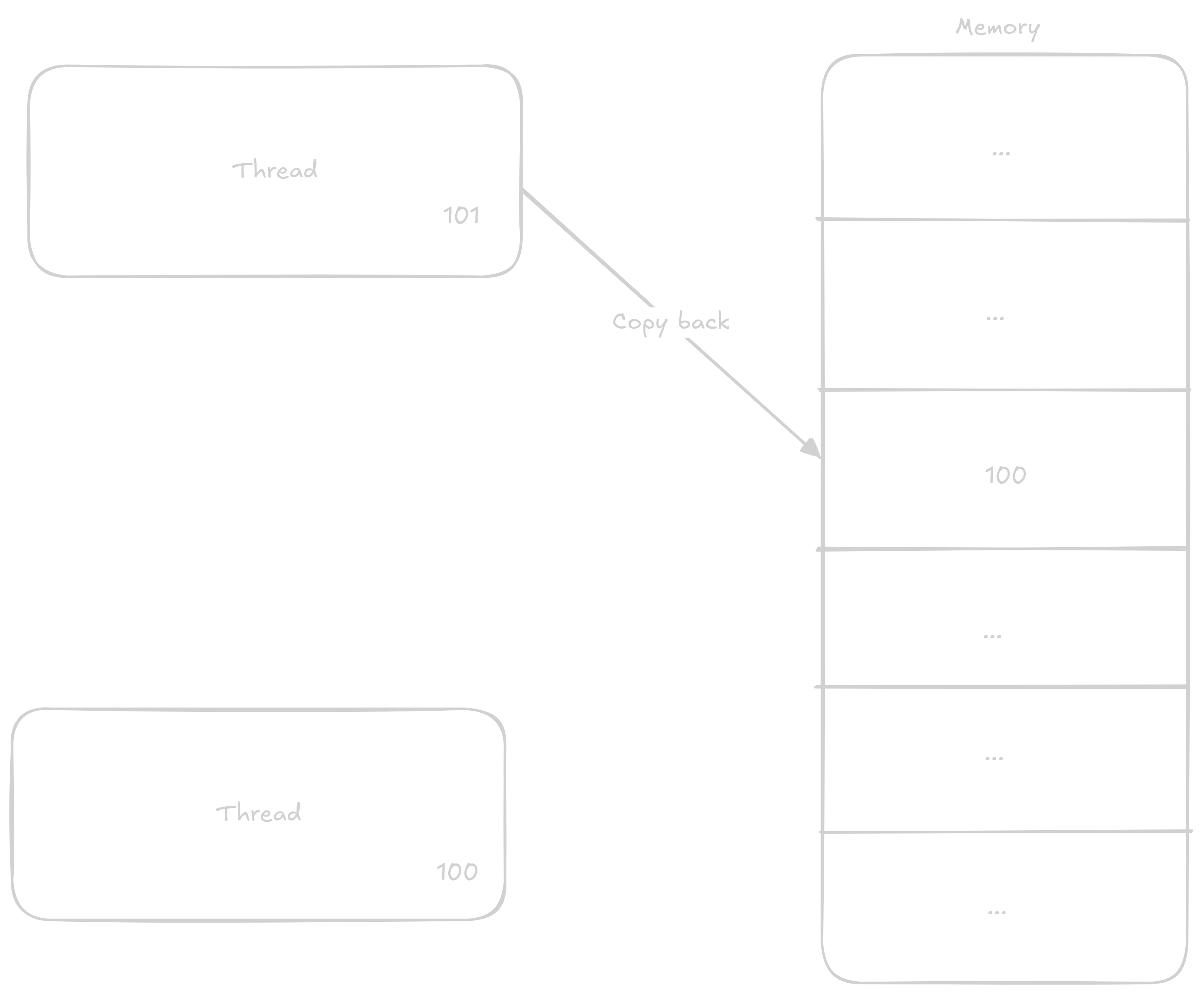
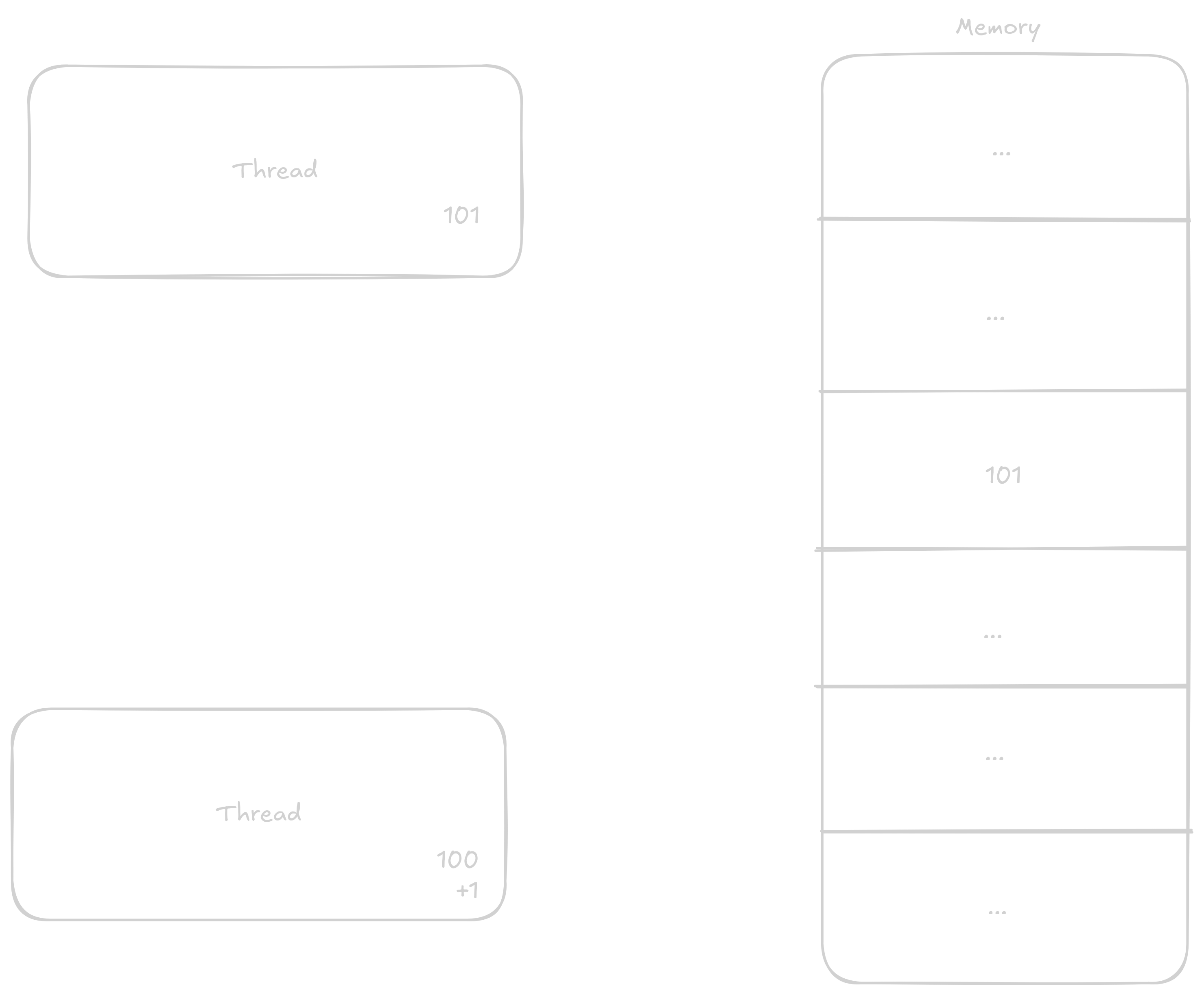
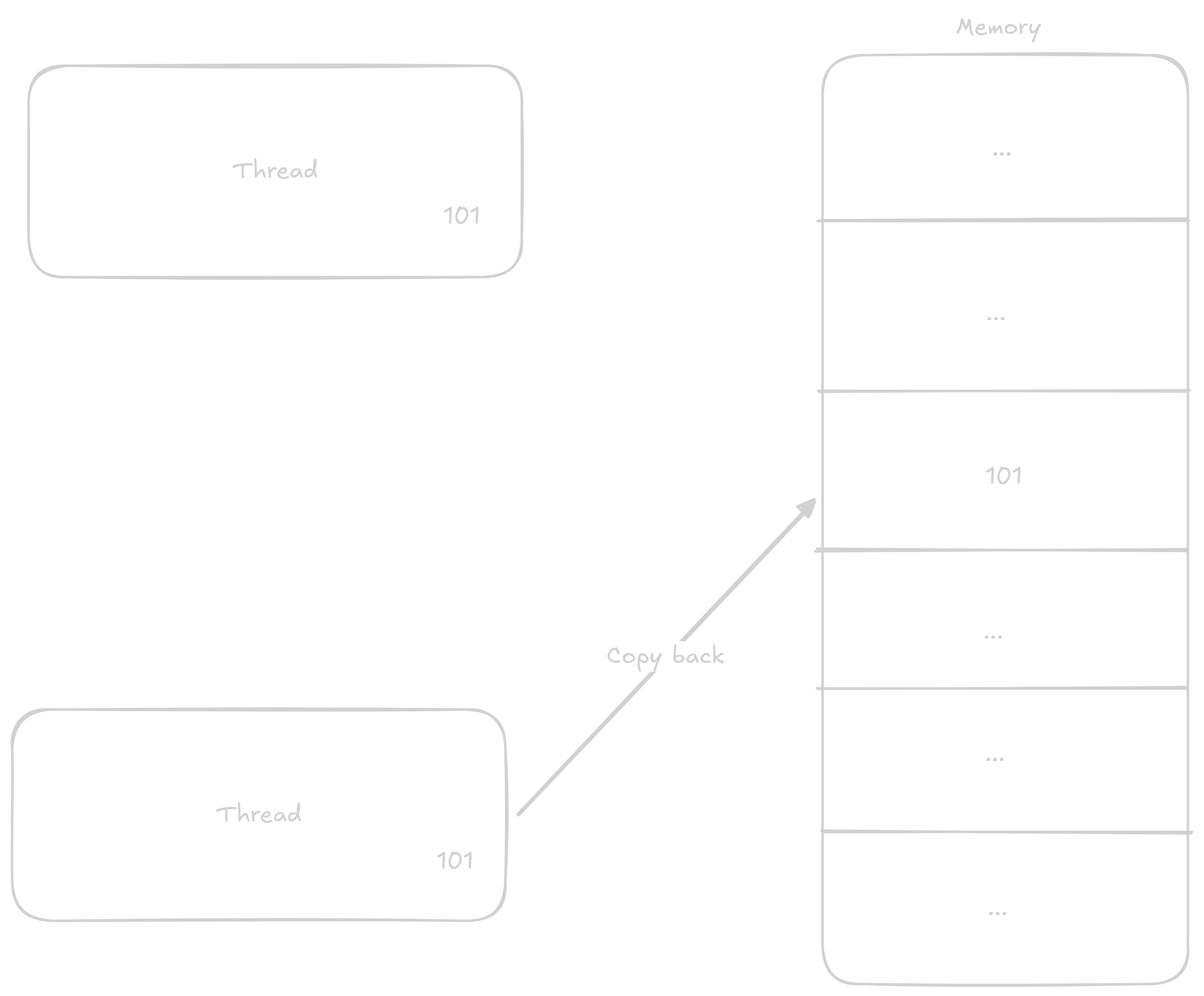
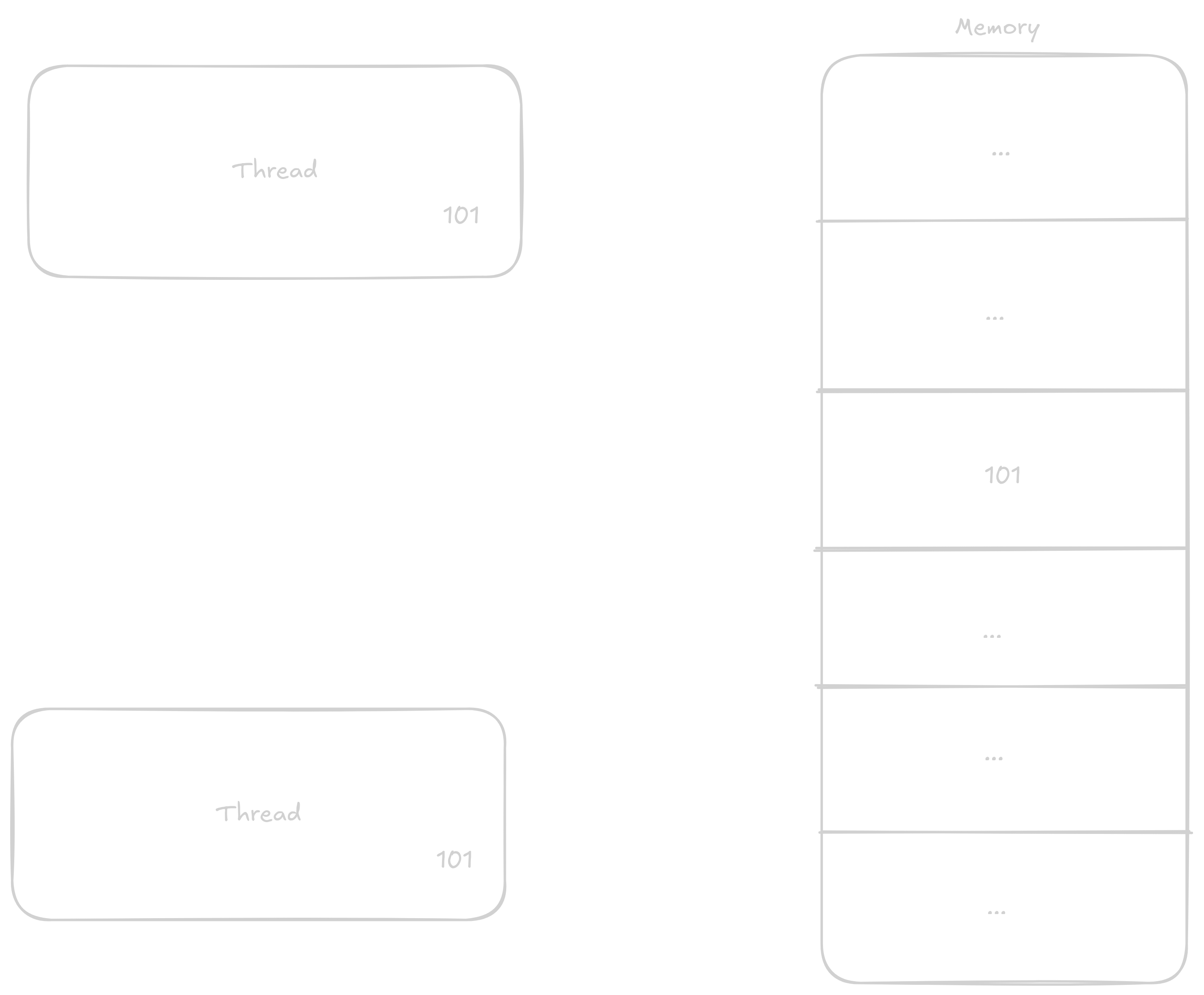
Takto i přes to, že měli proběhnout dvě přičtení proběhlo jen jedno.
Kvůli tomu výsledek výše napsaného programu bude něco jako count = 100000, count = 137269, count = 98455 nebo opět cokoliv mezi tím.
Tomuto problému říkáme race condition. Způsobu jakým se tomuto problému vyhnout se budeme věnovat v další kapitole.
Synchronicační datové struktury
Tyto datové struktury nám dovolují sdílet informace mezi jednotlivými jádry. Tato informace je nejčastěji: K tomuto zdroji nemáš přístup čekej nebo k tomuto zdroji máš přístup exkluzivně ty. Princip těchto struktur je postavený na takzvaných atomických operacích které se provedou celé naráz aniž by je mohlo něco přerušit.
Atomické operace
Nejčastější atomické operace jsou buď read-modify-write nebo instrukce které si načtou hodnotu z adresy a tuto adresu pak zablokují než do ní zapíší. Oba tyto typy fungují na stejném principu, že si procesor zapíše že všichni musí počkat pokud chtějí dělat něco s touto adresou. Read-modify-write instrukce načtou hodnoty udělají na nich operaci a hodnotu zase uloží v jedné instrukci zatímco druhý typ operací nechá programátora dělat co chce s hodnotami než jsou zase uloženy.
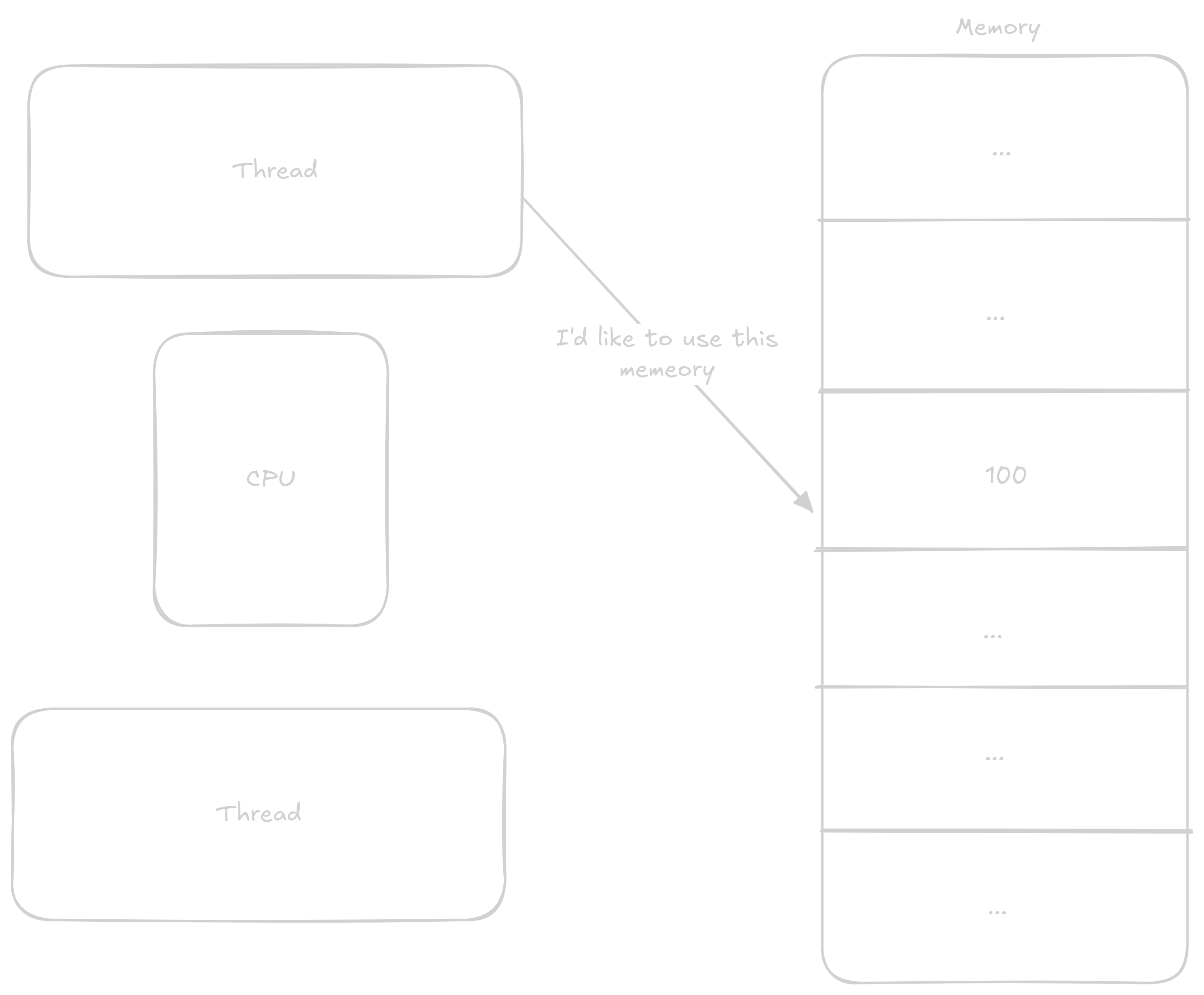
Jeden thread si zažádá o exkluzivní přístup k adrese
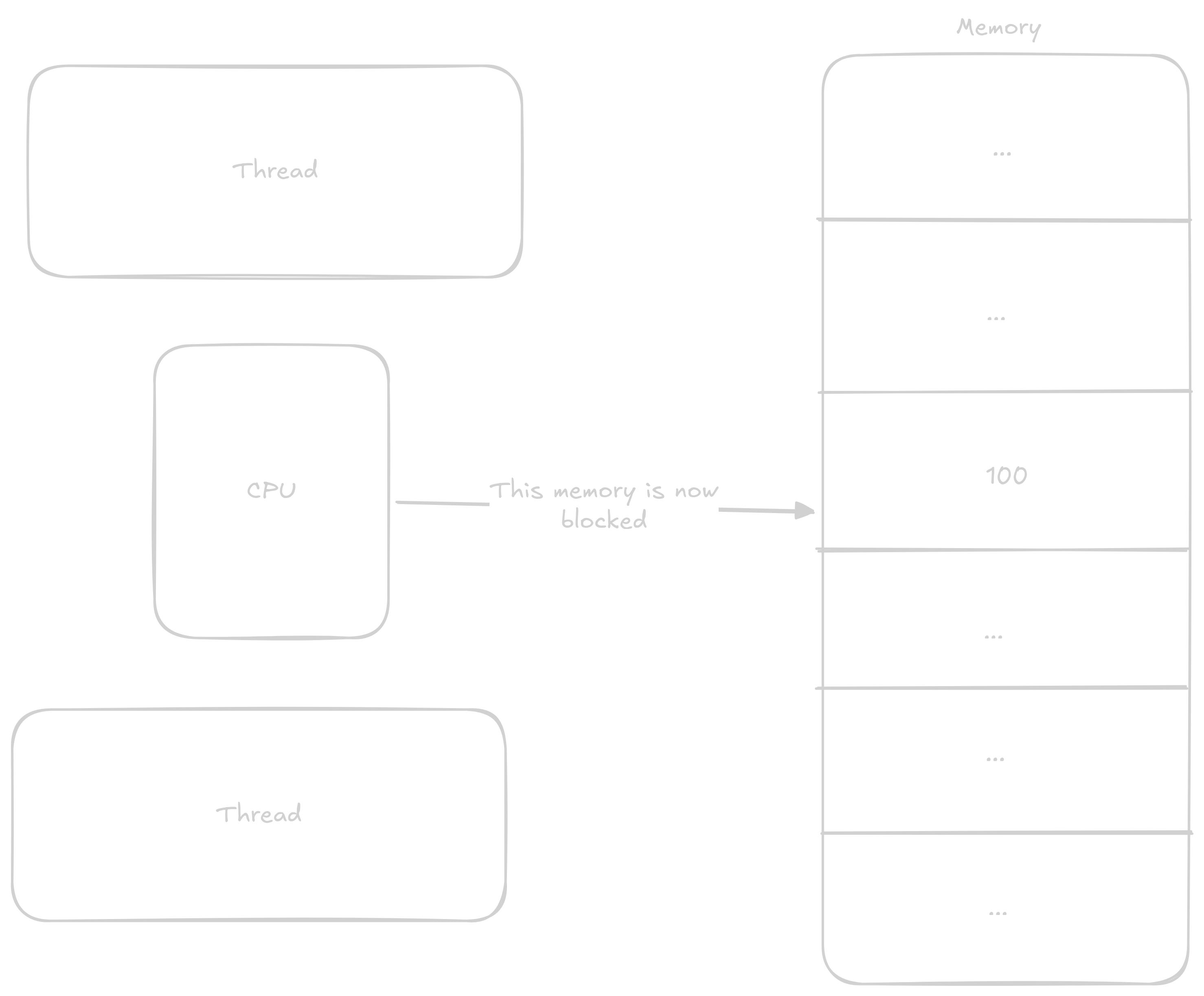
CPU zablokuje tuto adresu pro ostatní thready
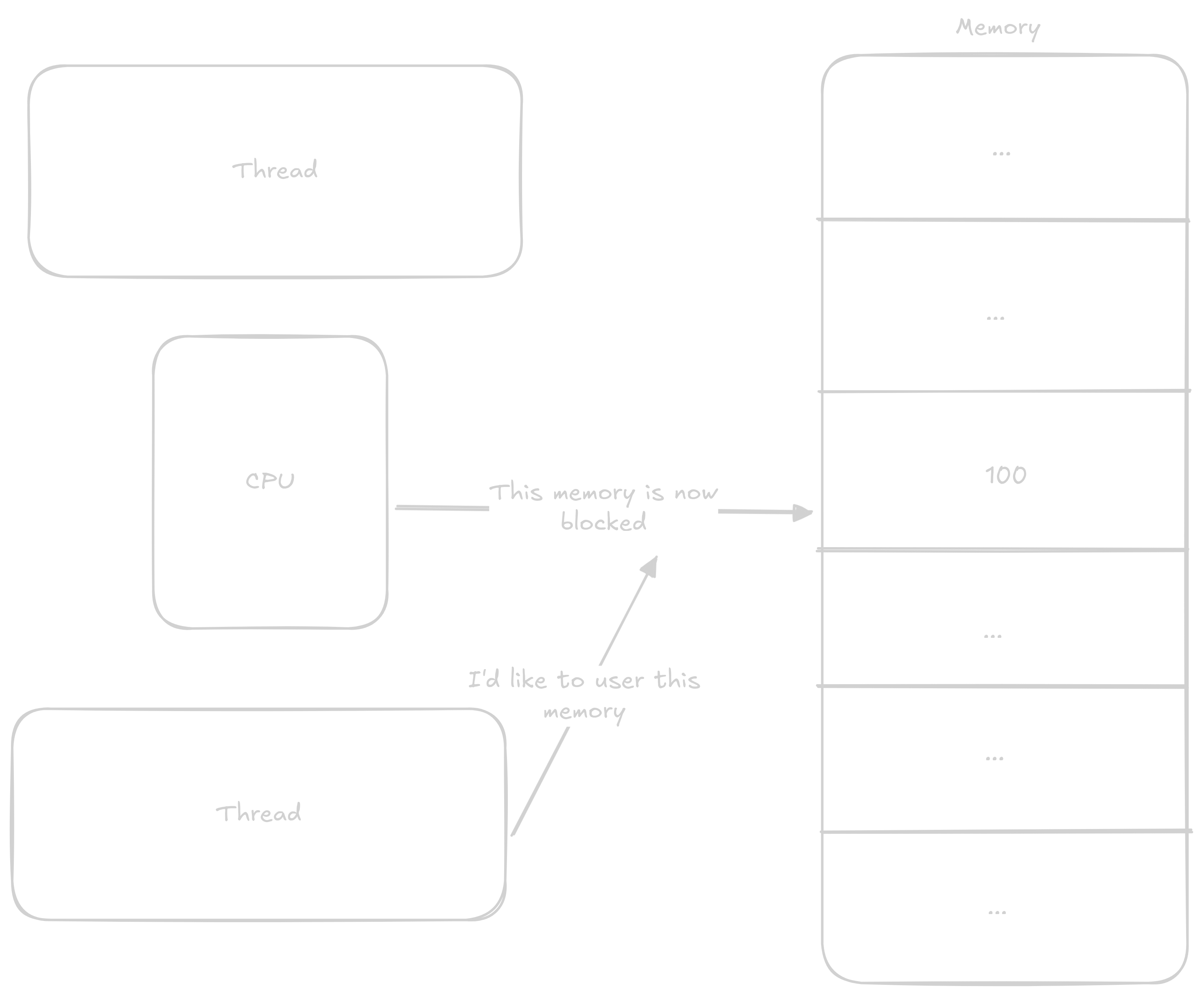
Zatímco první thread něco dělá s daty druhý chce použít tu samou adresu. Kvůli tomu že CPU adresu blokuje druhý thread musí čekat
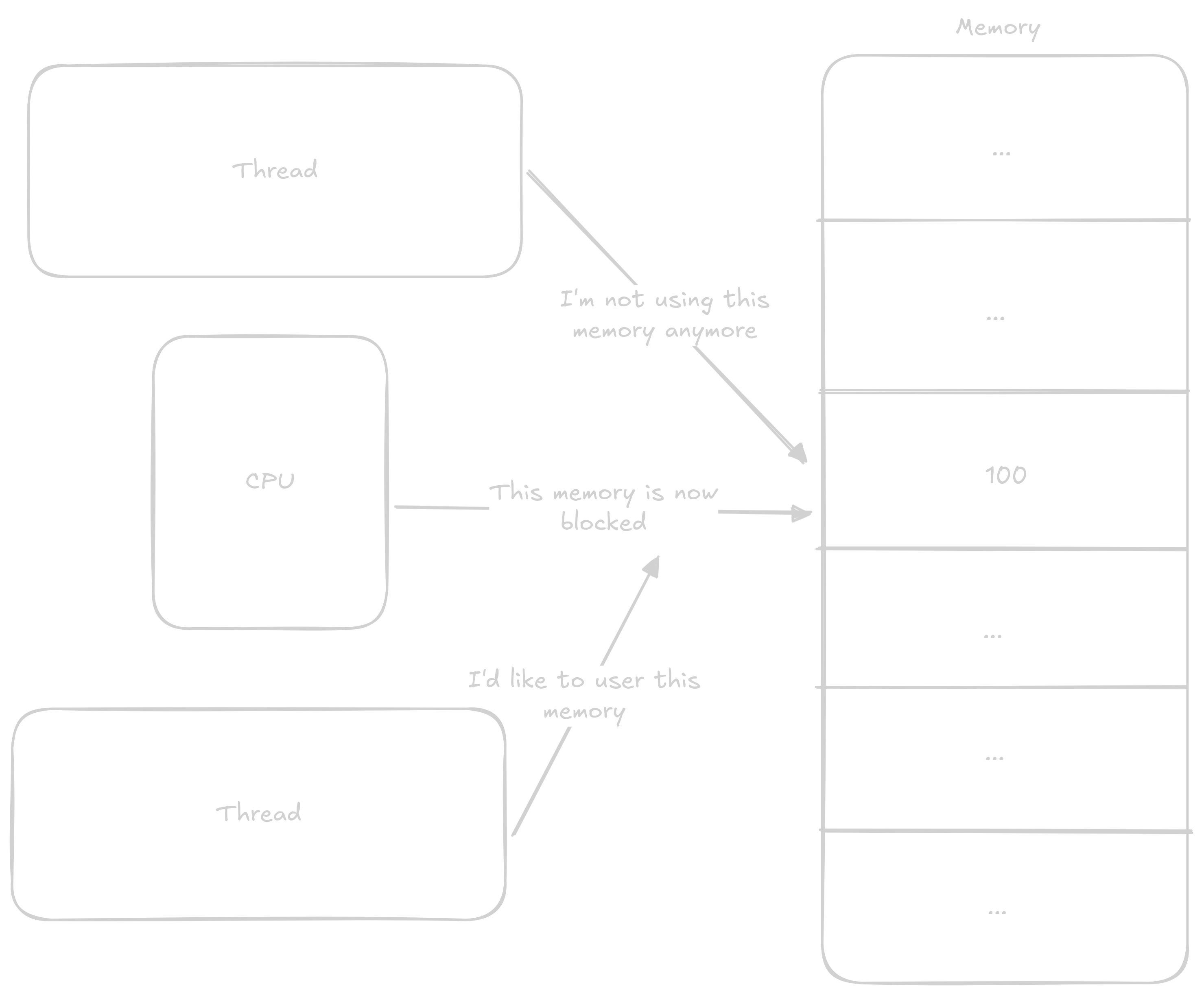
První thread zapíše výsledek a tím adresu zase uvolní
Druhý thread získá exkuzivní přístup k adrese
CPU opět zablokuje adresu
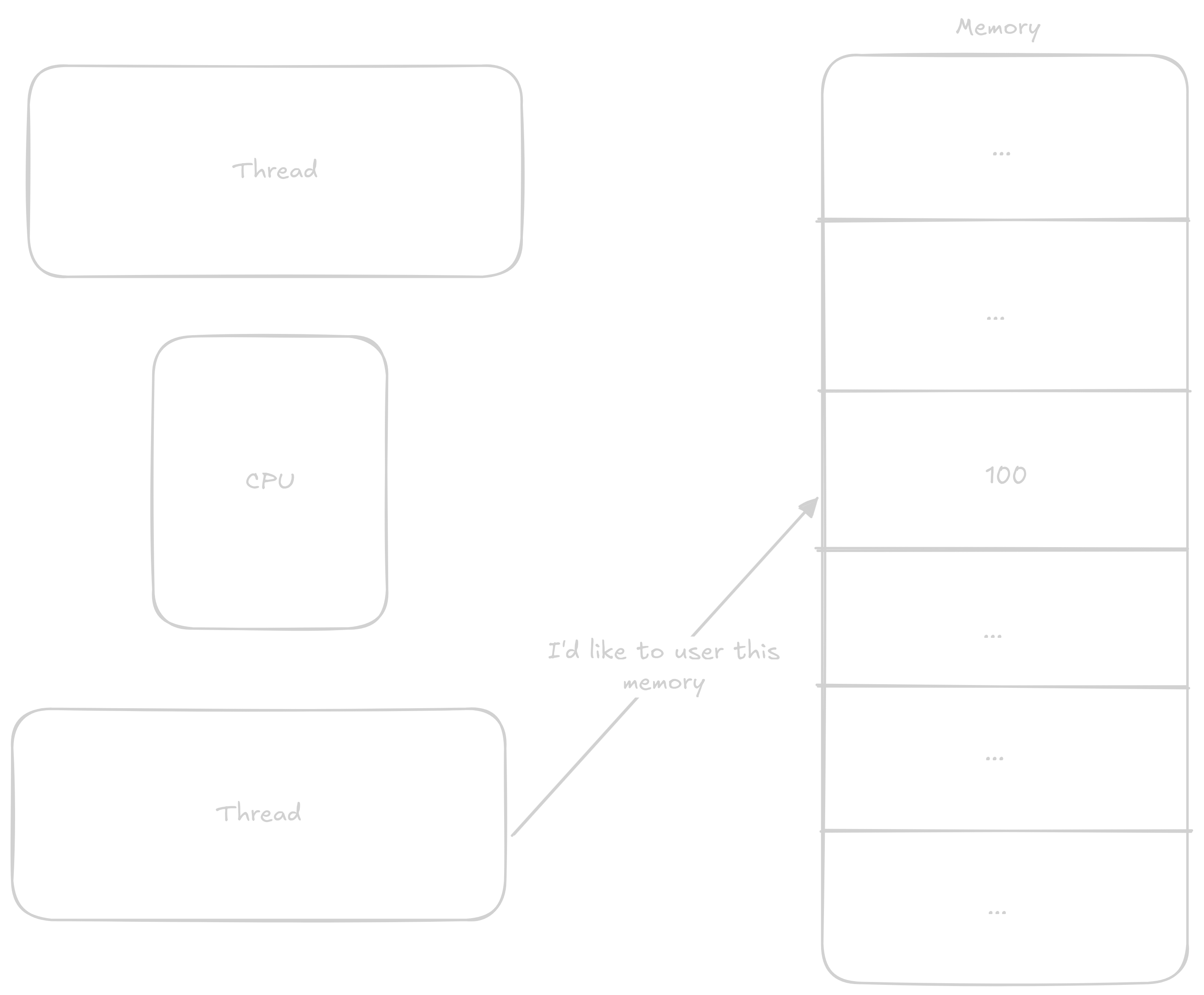
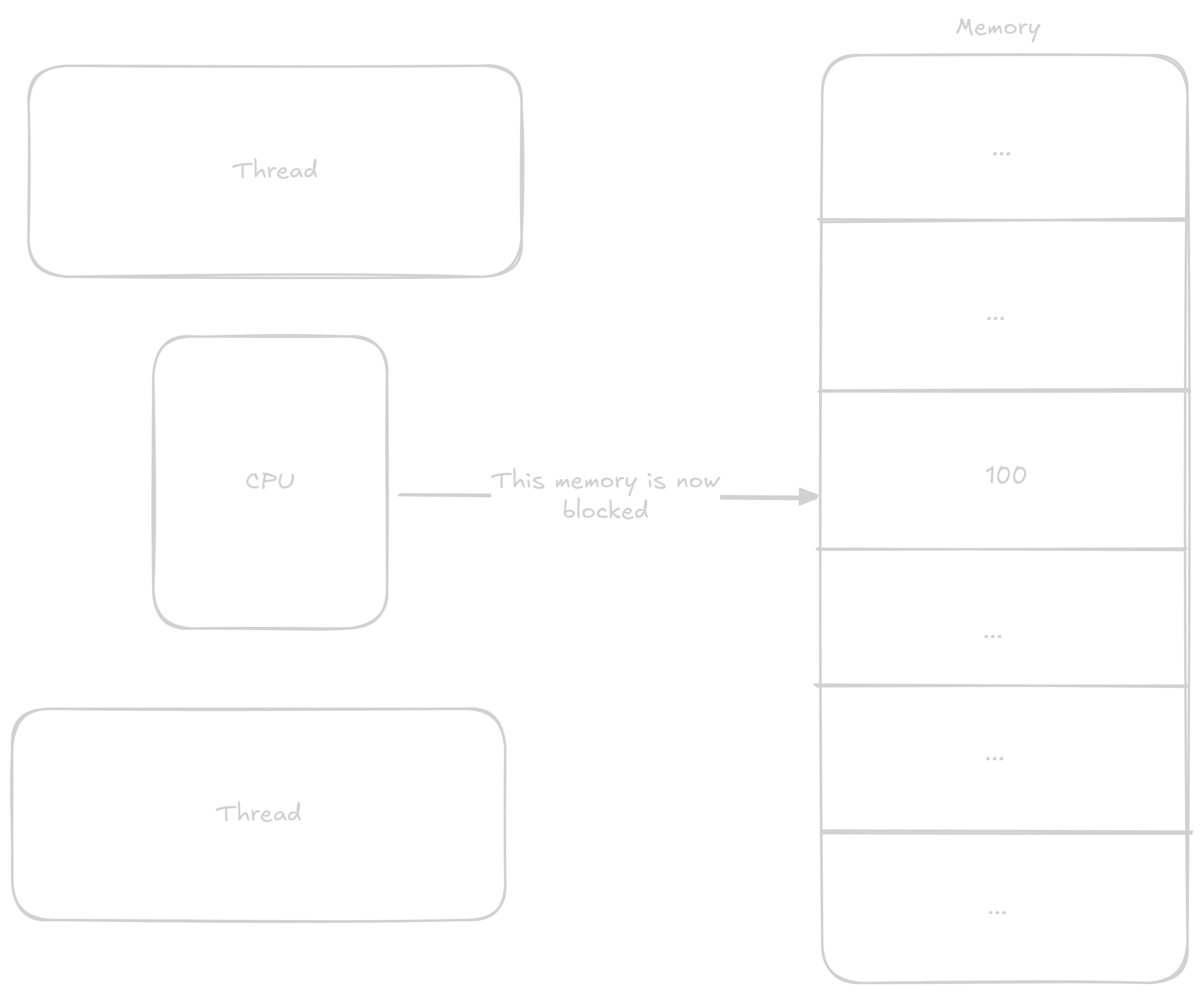
V předchozím programu kde jsme přičítaly k counter by šli atomicky přičítat k proměnné counter a tím se vyhnout výše zmíňené race condition.
Takový kód by vypadal takto:
#include <pthread.h>
#include <stdatomic.h>
#include <stdio.h>
// count bude typu atomic_int
atomic_int count = 0;
void *inc_count(void *arg) {
int i;
for (i = 0; i < 100000; i++) {
// zde atomicky přičteme 1 k proměné count
atomic_fetch_add(&count, 1);
}
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, inc_count, NULL);
pthread_create(&t2, NULL, inc_count, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("count = %d\n", count);
return 0;
}Tento kód vždy vytiskne count = 200000 protože máme na úrovni procesoru garantováno že k proměnné count vždy přičítá právě jeden thread.
Pojďme se nyní kouknout na tento kód:
#include <pthread.h>
#include <stdatomic.h>
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 200001
char buffer[BUFFER_SIZE];
atomic_int position = 0;
void *write_chars(void *arg) {
// přetypujeme a dereferencujeme argument z void pointeru na char
char c = *(char *)arg;
for (int i = 0; i < 100000; i++) {
if (position < BUFFER_SIZE - 1) {
// vložíme charakter na momentální pozici
buffer[position] = c;
atomic_fetch_add(&position, 1);
}
}
return NULL;
}
int main() {
pthread_t t1, t2;
char c1 = 'A', c2 = 'B';
memset(buffer, 0, BUFFER_SIZE);
pthread_create(&t1, NULL, write_chars, &c1);
pthread_create(&t2, NULL, write_chars, &c2);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
buffer[position] = '\0';
printf("Expected position: 200000\n");
printf("Actual position: %d\n", position);
int a_count = 0, b_count = 0, skipped_count = 0;
for (int i = 0; i < position; i++) {
if (buffer[i] == 'A')
a_count++;
else if (buffer[i] == 'B')
b_count++;
else if (buffer[i] == 0)
skipped_count++;
else
return 1;
}
printf("A's: %d, B's: %d, skipped: %d\n", a_count, b_count, skipped_count);
printf("Total characters written: %d\n", a_count + b_count);
return 0;
}Zde naplňujeme buffer písmenem A z jednoho threadu a písmenem B z druhého threadu.
I přes to že bychom mohly očekávat že program poběží správně díky tomu že používáme atomické přičítání opět se setkáme s naším výše zmíněným nepřítelem race condition.
Tentokrát nastane race condition mezi těmito dvěmi řádky:
buffer[position] = c;
atomic_fetch_add(&position, 1);Důvod je že se operace stanou v tomto pořadí:
První vlákno zapíše na momentální pozici
positionDruhé vlákno zapíše na momentální pozici
positionPrvní vlákno atomicky přičte k
positionDruhé vlákno atomicky přičte k
position
Obě jádra tedy zapíšou na tu samou pozici a pak obě přičtou k position čímž kompletně přeskočí jednu pozici.
Výstup tohoto programu proto bude vypadat nějak takto
Expected position: 200000
Actual position: 200000
A's: 99358, B's: 99641, skipped: 1001
Total characters written: 198999position má správnou hodnotu protože se vždy správně atomicky přičte, ale kvůli výše popsané race condition budou zápisy do něktérých pozic v buffer přeskočí.
Zde můžeme vidět, že toto není nejlepší způsob jak pracovat z atomickými operacemi a že budeme muset vytvořit nějáký robustnější způsob jak zabránit race conditions.
Mutex
Mutex nebo mutual exclusivity je synchronizační datová struktura která dovoluje vždy právě jednomu vláknu přistupovat k zdroji. Pokud k tomuto zdroji chce přistoupit druhé jádro musí počkat než se první jádro zdroje "vzdá".
Mutex má dvě hlavní operace zamknout a odemknout (budu používat zaměnitelně s lock a unlock) Lock buď mutex uzamkne nebo čeká než se mutex odemkne a pak ho uzamkne a unlock mutex prostě odemkne.
Implementace
V principu potřebujeme signalizovat dva stavy zamčeno a odemčeno což může jedno číslo které bude mít hodnotu 1 nebo 0.
typedef struct {
atomic_int flag;
} simple_mutex;Toto je všechno co je pro modelování mutexu potřeba.
Nyní použijeme několik nových konstruktů z stdatomic.h knihovny.
Prvním je atomic_init() kterým mutex inicializujeme:
void simple_mutex_init(simple_mutex *mtx) {
// nastavíme úvodní hodnotu flag na 0
// 0 značí že je mutex uvlolněný
atomic_init(&mtx->flag, 0);
}Na uzamčení mutexu musíme použít o něco komplikovanější atomic_exchange().
void simple_mutex_lock(simple_mutex *mtx) {
while (atomic_exchange(&mtx->flag, 1) == 1) {
// Spin
}
}Atomic exchange nám vrátí hodnotu která původně byla na adrese uložena.
Co zde mi děláme je, že čekáme než se předchozí hodnota flag nebude rovnat 1 (tedy že se bude rovnat 0).
V chvíli kdy se předchozí hodnota flag nebude rovnat 1 znamená to že jiný thread mutex uvolnil a mi jsme ho pomocí exchange okamžitě zase zamknuly a loop skončí.
Nakonec odemknutí je pouhé uložení 0 do flag pomocí atomic_store().
void simple_mutex_unlock(simple_mutex *mtx) {
atomic_store(&mtx->flag, 0);
}Celý zdrojový kód mutexu si můžete stáhnout zde a header file zde.
Využití
Teď když máme mutex můžeme ho využít abychom opravily race condition v předchozím programu.
#include "simple_mutex.h"
#include <pthread.h>
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 200001
char buffer[BUFFER_SIZE];
int position = 0;
simple_mutex mtx;
void *write_chars(void *arg) {
// přetypujeme a dereferencujeme argument z void pointeru na char
char c = *(char *)arg;
for (int i = 0; i < 100000; i++) {
// v tuto chvíli zamykáme mutex a na buffer a position můželse přistupovat
// pouze toto vlákno
simple_mutex_lock(&mtx);
if (position < BUFFER_SIZE - 1) {
// vložíme charakter na momentální pozici
buffer[position] = c;
position++;
}
simple_mutex_unlock(&mtx);
}
return NULL;
}
int main() {
pthread_t t1, t2;
char c1 = 'A', c2 = 'B';
// incializace mutexu
simple_mutex_init(&mtx);
memset(buffer, 0, BUFFER_SIZE);
pthread_create(&t1, NULL, write_chars, &c1);
pthread_create(&t2, NULL, write_chars, &c2);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
buffer[position] = '\0';
printf("Expected position: 200000\n");
printf("Actual position: %d\n", position);
int a_count = 0, b_count = 0, skipped_count = 0;
for (int i = 0; i < position; i++) {
if (buffer[i] == 'A')
a_count++;
else if (buffer[i] == 'B')
b_count++;
else if (buffer[i] == 0)
skipped_count++;
else
return 1;
}
printf("A's: %d, B's: %d, skipped: %d\n", a_count, b_count, skipped_count);
printf("Total characters written: %d\n", a_count + b_count);
return 0;
}Teď už program vytiskne očekáváný výstup:
Expected position: 200000
Actual position: 200000
A's: 100000, B's: 100000, skipped: 0
Total characters written: 200000Díky mutexu vždy zapsání do bufferu a přičtení k position proběhne naráz aniž by jiné vlákno v té chvíli mohlo něco provést.
Tyto operace provádí vždy právě jedno vlákno a všechny ostatní vlákna musí počkat než se mutex ovolní než budou moct tyto operace provést.
Pokud budete chtít mutex používat v reálném programu je lepší používat mutext přímo z knihovny pthread.h.
Mutex v této knihovně je lépe napsaný a otestovaný.
Výše napsaná implementace mutexu je vhodná pouze pro vzdělávací účely
#include <pthread.h>
int main() {
pthread_mutex_t mtx;
pthread_mutex_init(&mtx, NULL)
pthread_mutex_lock(&mtx);
pthread_mutex_unlock(&mtx);
pthread_mutex_destroy(&mtx);
}Kdy mutex použít
Mutexy jsou vhodné pro chvíle kdy více threadů potřebuje číst a zapisovat do nějákého zdroje ať už je to string nebo cokoliv jiného. Výhoda mutexu je že je velmi jednoduché ho zaintegrovat do svého kódu. Kdykoliv k sdílenému zdroji přistupujete, před přístupem mutex zamknete a v chvíli kdy zdroj nepotřebujete mutex zase odemknete.
Nevýhoda mutexu je to že je velmi jednoduché ho použít špatně. Mutex efektivně dělá nějakou část kódu sekvenční a je jednoduché se zbavit jekéhokoliv zrychlení které mohl multithreading přinést tím že přidáme mutex na špatné místo.
Mutex také není vhodné používat v chvíli kdy něteré thready potřebují zdroj pouze číst a jen některé zapisovat, nebo v chvíli kdy se občas dělají zápisy a zbytek času se pouze čte. V těchto případech je vhodnější používat jinou strukturu.
Read Write Lock
Read Write Lock nebo rwlock je struktura podobná jako mutex s tím rozdílem že dovoluje neomezený počet přístupů na čtení nebo jeden přístup na zápis. Tato struktura je vhodná v chvílích kdy není potřeba vždy zapisovat ale často bude stačit pouze čtení.
Implementace
Je několik způsobů jak modelovat rwlock, já zde ukážu jeden z nejjednodušších způsobů využívající dva mutexy, ale jsou i třeba způsob využívající pouze jedno číslo. (Mutex je takový základní stavební kámen dalších synchronizačních datových struktur)
Jeden mutex bude "bránit" počet readers aby šli přidávat a odebírat readers. Druhý mutex se bude zamykat pokud bude víc než jeden čtenář nebo právě jeden zapisovatel.
typedef struct {
int readers;
pthread_mutex_t readers_lock;
pthread_mutex_t writer_lock;
} simple_rwlock;Nejdříve musíme rwlock inicializovat při čemž inicializujeme mutexy z pthread.h knihovny a nastavíme readers na 0.
void simple_rwlock_init(simple_rwlock *rw) {
rw->readers = 0;
pthread_mutex_init(&rw->readers_lock, NULL);
pthread_mutex_init(&rw->writer_lock, NULL);
}Rwlock má dvě lock a dvě unlock operace. Jedna sada lock unlock je pro read operace a druhá pro write operace.
Reader
Reader lock přidá readera a zabrání v vytváření zapisovatelů.
void simple_rwlock_rlock(simple_rwlock *rw) {
// Zamkeme mutex aby nevznikl race condition při upravování hodnoty readers
pthread_mutex_lock(&rw->readers_lock);
rw->readers++;
if (rw->readers == 1) {
// pokud je toto první čtenář, zamkneme writer lock
// V případě že se mezitím writer tento lock zamknul
// bude zde mutex čekat dokud se zase neuvolní.
pthread_mutex_lock(&rw->writer_lock);
}
// opět uvolníme reader mutex aby mohly být přidáni další čtenáři
pthread_mutex_unlock(&rw->readers_lock);
}Reader unlock pro se moc neliší a hlavně oddělává práci locku (I know stating the obvious).
void simple_rwlock_runlock(simple_rwlock *rw) {
// stejně jako u rlock zamkneme mutex aby nenastal race condition
pthread_mutex_lock(&rw->readers_lock);
rw->readers--;
if (rw->readers == 0) {
// pokud je odebrán poslední čtenář, uvolníme writer lock
// protože je bezpečné zapisovat
pthread_mutex_unlock(&rw->writer_lock);
}
pthread_mutex_unlock(&rw->readers_lock);
}Writer
Writer má operace značně jednodušší.
Stačí aby zamknul writer lock čím který bude odemčený pokud je 0 čtenářů i zapisovatelů a jehož zamknutí zabrání vytvoření jak nových čtenářů tak zapisovatele.
void simple_rwlock_wlock(simple_rwlock *rw) {
// writer lock je zamknutý dokud je někdo v čtení
// dokud je tento mutex zamknutý není možné přidat čtenáře
pthread_mutex_lock(&rw->writer_lock);
}Unlock poté prostě writer lock odemkne.
void simple_rwlock_wunlock(simple_rwlock *rw) {
// po dokončení zápisu uvolníme writer lock
pthread_mutex_unlock(&rw->writer_lock);
}Využití
Stejně jako u mutexu tato implementace je pouze pro vzdělávací účely používejte implementaci z pthread.h
#include <pthread.h>
int main()
{
pthread_rwlock_t rwlock;
pthread_rwlock_init(&rwlock, NULL);
pthread_rwlock_rdlock(&rwlock);
pthread_rwlock_unlock(&rwlock);
pthread_rwlock_wrlock(&rwlock);
// zde stačí pouze jeden typ unlock protože rwlock dokáže zjistit
// zda je zrovna potřeba uvolni read lock nebo writer lock
pthread_rwlock_unlock(&rwlock);
pthread_rwlock_destroy(&rwlock);
return 0;
}Jak již bylo zmíněno výše rwlock je vhodný pro místa kde je často potřeba číst a někdy zapisovat. Mezi takové systémy například patří cache, configuration managers nebo například databáze.